

?你有没有想过,当我们在搜索框中输入关键词时,搜索引擎是如何确定返回哪些内容给你的?搜索引擎底层有一个巨大的索引库,返回的搜索结果跟你输入的关键词又有什么关系?今天我们就来讲讲搜索引擎中的召回。

召回是根据输入的query,能够高效的获取query相关的候选doc集合的过程。相关的doc如果不能被被召回,即使后面的粗排、精排做的再好也是徒劳无功。所以召回对于搜索引擎是非常重要的,决定了搜索引擎质量的上限。
本文主要讲解两类召回算法,包含基于词的传统召回和基于向量的语义召回。
基于词的召回底层实现基于倒排索引,在上一篇《索引技术》我们有讲到过,倒排索引如何建立以及它的索引结构,当用户输入query后,搜索引擎会进行query理解(具体流程可参考《详解query理解》)并分词,得到一个个独立的[Term1、Term2.....TermN],根据这些词到倒排索引中进行查找Term所在的文档即完成了召回。拿之前的例子来讲,倒排索引如下:
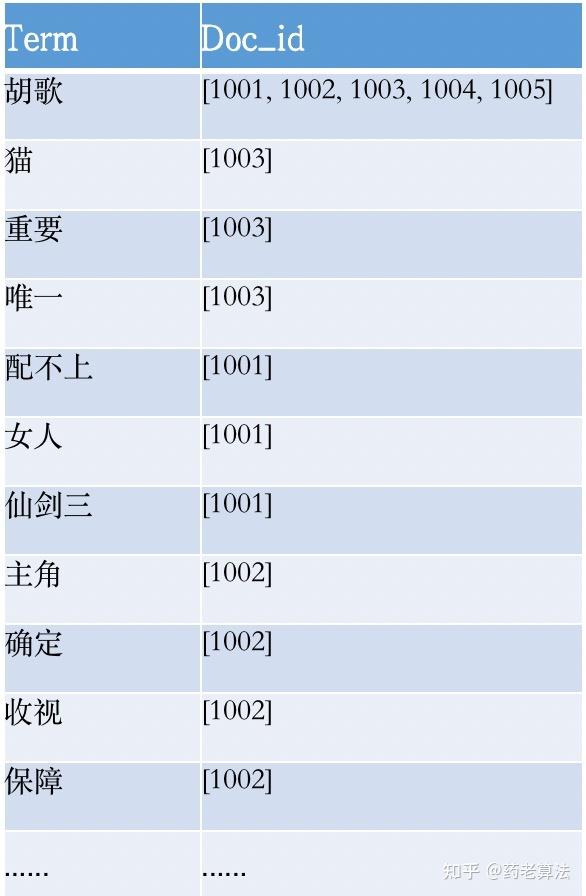
如果用户输入“胡歌猫”,那么“胡歌”和“猫”分别会找出对应的倒排索引,“胡歌”对应的[1001,1002...],“猫”对应的是[1003]。那么就有人会问了,每个Term都会查询倒排,最终是如何召回哪些呢?这里涉及到召回截断和搜索性能问题了。
召回截断:query理解中有讲到,关键词分词成不同的Term,也会对应不同的权重,每个Term查询倒排索引都会有一个倒排链,并且可以基于每个倒排索引定制一个召回分数,召回分数可以根据索引的点击量,索引的时间顺序等自定义规则进行打分,最后我们可以根据权重和召回分数大小,对于弱相关性的倒排索引召回进行截断。
搜索性能:在于大数据体量的搜索内容池中,我们考虑搜索性能,则可以针对Term对应的倒排链取交集,最终同时包含Term1,Term2...TermN的倒排索引才进行召回,减少召回量。
召回多样性:召回还需要保持多样性。同一个Term可能会召回很多不同类型的索引,比如你搜索"斗罗大陆",召回的类型可能有小说、视频、百科、游戏,但仅仅根据召回分数进行截断,可能会导致召回不全或者召回不准,所以每个Term应该在每种类型的数据项召回合适的数量,从而保证相关性和多样性。
在开源的搜索引擎中大多数都是基于词的传统召回方式,比如像TF-IDF,BM25,F1EXP等算法,这种基于关键词的有一个弱点,无法召回语义相似性的结果。例如有两个query:“iphone多少钱”和“苹果手机什么价格”,这两个query的意思基本一致,同样想知道iPhone手机的价格,但是字面上没有任何的重叠,用传统算法计算相似度非常低。不仅如此,还包含“儿童用品”与“玩具”,“床上用品”与“被子”等电商垂搜领域的语义相似词,都存在基于词无法召回的情况。
基于向量的语义召回就是解决词不同但是义相似的召回问题。
【基于DSSM的深度召回模型】
DSSM是Deep Structured Semantic Model的缩写,基于深度网络的语义模型,由微软研究院在2013年发表,其其核心思想是基于搜索引擎的曝光点击行为数据,利用多层DNN网络把query及文档Doc Embeding成同一纬度的语义空间中,通过最大化约束query和doc两个语义向量的余弦举例,从而训练学习得到隐层相似度语义模型,从而实现了检索召回。
下图是DSSM模型的网络结构图
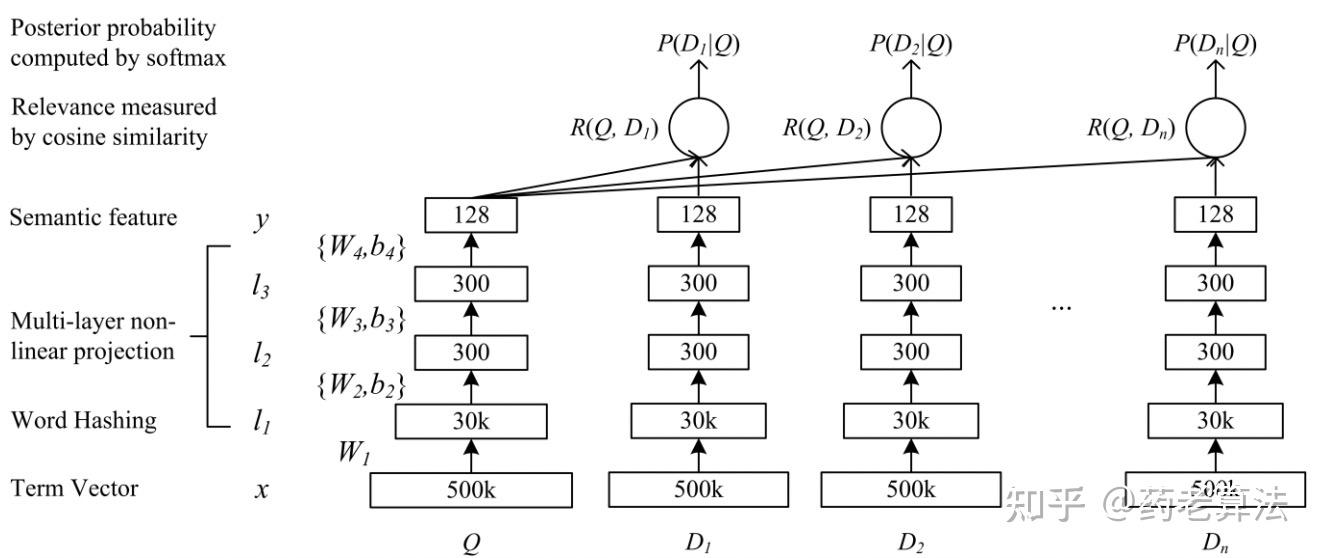
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层。
输入层:将所有query以及候选集doc映射到统一空间并作为输入,放进DNN中进行训练,但在DSSM中,中英文的处理方式有所不同。英文一般直接使用word hashing,3个字母为一组,#表示开始和结束符。而中文依赖于分词,中文分词本身就比较难,中文语义性太强,中文词语有近百万个,在网络中维度太高不利于训练,所以DSSM中文输入层可以模拟英文处理,使用单字分词,字向量(one-hot)作为输入,向量空间约为 1.5 万维。
表示层:采用 BOW(Bag of words)的方式,相当于不考虑文本的字符顺序和上下关系,将整个句子里的词都放在一个袋子里了。一个含有多个隐层的DNN,公式如下图,用Wi 表示第i层的权值矩阵,bi表示第i层的 bias 项。第一隐层向量l1(300 维),第i个隐层向量li(300 维),输出向量 y(128 维)。
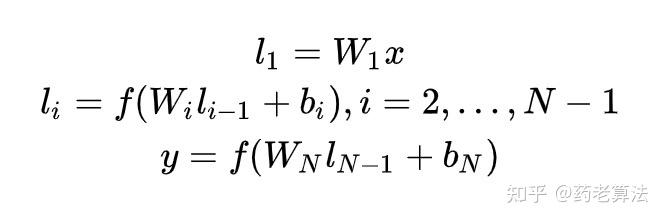
最后用 tanh 作为隐层和输出层的激活函数:
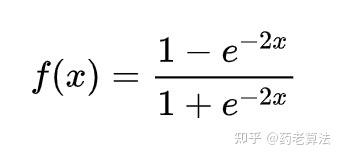
最终输出一个 128 维的低纬语义向量。
匹配层:在召回匹配过程,我们使用 Q 来表示一个query,D 来表示一个doc,那么他们的相关性分数可以用下面的公式衡量:
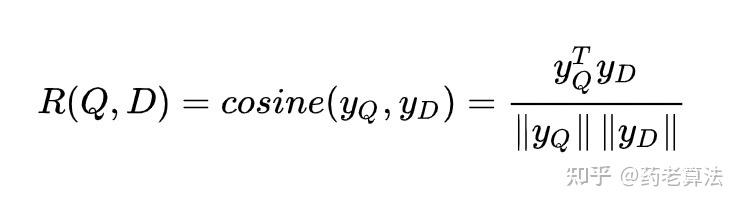
其中,yQ 与 yD 分别代表query和doc的语义向量。在搜索引擎中,给定一个query,会返回一些按照相关性分数排序的文档。
DSSM有一定的缺点,因为丢失了文本的字符顺序和上下文信息,所以有很多进化模型,比如CNN-DSSM和LSTM-DSSM,感兴趣的朋友可以研究研究。
【基于DPSR的个性化召回模型】
DPSR是京东发表于 SIGIR 2020 的paper,文章为京东在搜索推荐系统领域的实践经验总结,介绍了自 2019 年就部署在京东上的搜索推荐系统框架DPSR,总体网络结构如下:
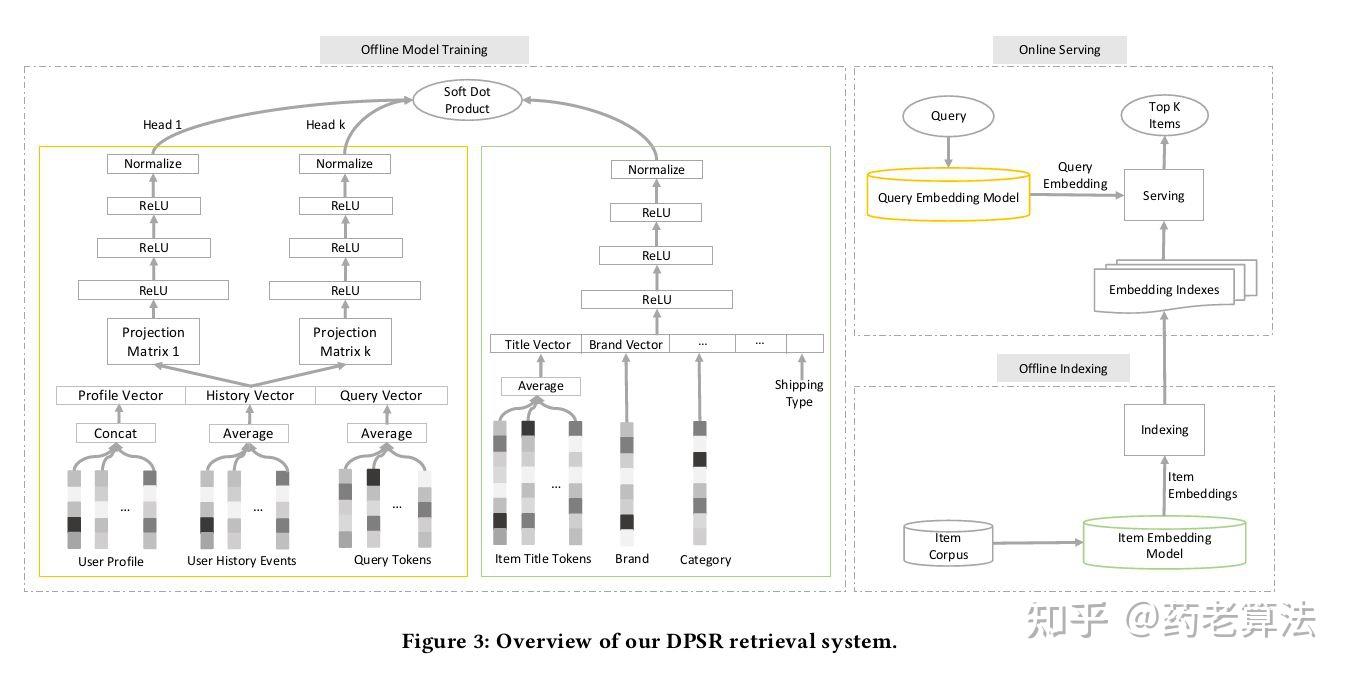
从整体看,离线模型是一个双塔模型结构,query 和 item 分别有一个 model tower。
Query 端:包括query tokens、user profile、user history events 等特征。
item端:包括 title tokens、brand、category、shopid 等特征。
离线索引(offline indexing):使用的是item tower,导出item的embedding 构建 QP 索引。
在线服务(online serving):使用的是query tower,实时计算Query Embedding,模型加载在tensorflow service,在线召回 TopK Item。
整个模型并不复杂,现在很多搜索推荐的召回算法中都有类似的想法,就是把用户和个性化信息作为一个tower,item信息作为另一个tower,然后通过多层的感知机进行训练建模,最后计算相似度排序召回。
【基于Bert预训练召回模型】
BERT是近年来NLP领域最重大的研究进展之一,相信NLP领域无人不知,这里就不多做介绍了,如果不了解可以搜索,有很多文章介绍BERT。其网络结构如下:
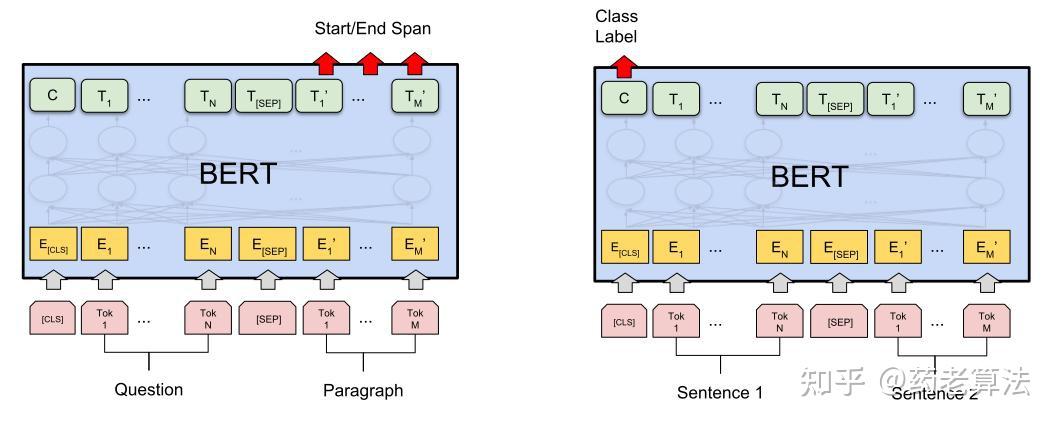
借鉴BERT经典的孪生网络结构,基于BERT模型分别做query和doc的encoder,接着用pooling之后的query和doc的向量计算余弦距离当做输出,最后通过pairwise损失函数训练模型。
pooling方法上,可以尝试不同层 pooling,或者在多层上增加attention机制聚合BERT多层结果,效果和最后一层所有token做average pooling应该是差不多。
损失函数方面,因为我们是做召回阶段的模型,引入Pairwise Approach模式,原始BERT使用Pointwise模式优化的目标是单条query与doc之间的相关性,即回归的目标是label。而Pairwise方法的优化目标是两个候选文档之间的排序位次(匹配程度)。
Bert模型多头的注意力机制和双向encoding让BERT的无监督训练更有效,并且使得BERT可以构造更宽的深度模型。并且能够获取上下文相关的双向特征表示,预训练模型无需你再使用大数据量训练文本模型,只需要根据特定任务的进行fine-tune即可。

最后欢迎关注同名微信公众号:药老算法(yaolaosuanfa),带你领略搜索、推荐等数据挖掘算法魅力。

